malloc_consolidate利用
最后更新时间:
文章总字数:
预计阅读时间:
比较强大的一个漏洞 触发的条件很常见 但是效果却很强大 在做NKCTF2023的时候作为压轴题考察了 后来才知道是原题 heapstorm zero
malloc_consolidate()
核心的利用就是依靠这个函数 这个函数有两种作用 第一是可以合并fastbinchunk 第二个是对于堆进行初始化
在学习fastbin中 我们知道 chunk被释放到fastbin后 其next chunk的Inuse位是不会被置零的
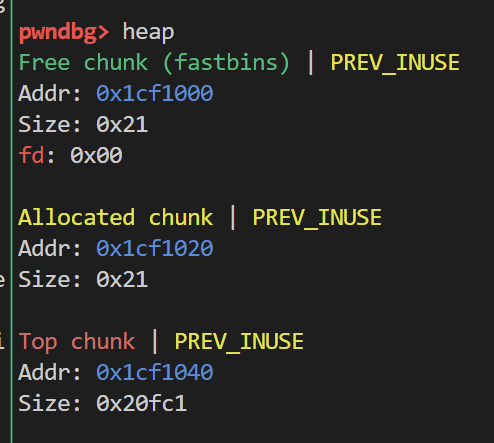
也就不会存在合并chunk这种利用方法
但是malloc_consolidate函数却可以实现合并fastbin的效果 按照上图的情形 此时触发malloc_consolidate函数 chunk0就会被放入到unsortedbin中 随后根据大小分配到smallbin中
我们先来讲其实现逻辑 触发条件稍等讲
1 | if (get_max_fast () != 0) { |
函数开始执行时 会对于get_max_fast ()的返回值进行判断 如果进程是第一次调用malloc函数时 其返回值为0 此时就会进行堆初始化工作
如果堆已经初始化完成 此时会调用clear_fastchunks函数清空fastbin的Inuse位
接着会进行一个嵌套循环 第一次循环遍历fastbin数组 得到链表 随后遍历链表 得到free chunk
1 | /* |
对于合并来说 首先是考虑向后合并 这里的向后合并指的是向低地址处
顺便复习一下向后合并的条件
其会对当前chunk的Inuse位进行判断 是否可以和物理相邻低地址处的chunk合并 接着通过prev_size位来索引prev_chunk的地址
修改其size为合并后的总和 随后让chunk进入unlink函数
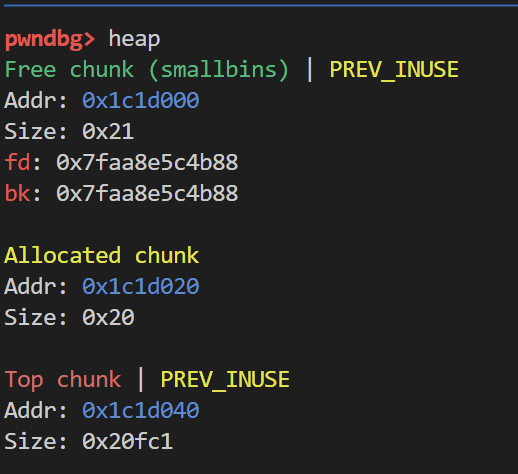
常见的就是topchunk合并 图例下面一并讲
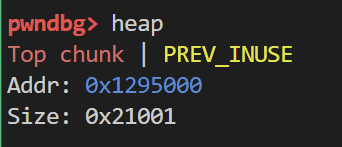
随后进入向前合并的分支 首先判断物理相邻高地址处的chunk是否为top chunk
如果为top chunk 则top chunk直接触发向后合并 如下所示布局堆
1 | add(0x10) |
如果nextchunk不为top chunk的话 则正式进入向前合并
1 | /* consolidate forward */ |
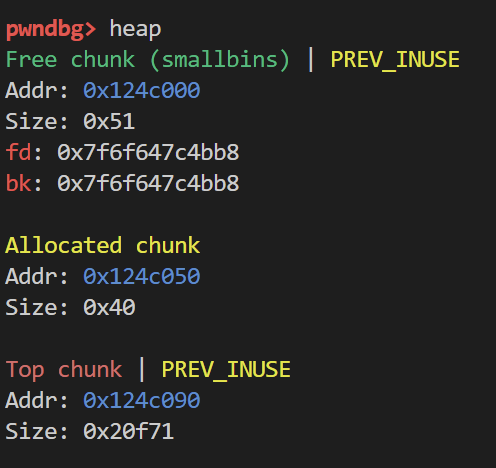
首先先索引到nextchunk 再索引到nextchunk的nextchunk 根据其的Inuse位来判断是否nextchunk被释放 如果被释放 如下图所示

那么就会合并chunk0和chunk1
如何触发
malloc_consolidate函数的强大功能我们上面已经了解到了 利用这一函数 可以轻松的获取smallbin或者largebin中的chunk
对于有些题目来说 其会对申请chunk的size进行限制 利用这一函数就可以绕过限制 仍然获得释放chunk到这两个bin中的机会
首先我们要知道 c语言中的标准输出和标准输入和标准错误都有着缓冲区 只不过其各自遵守的缓冲区原则不同
具体的可以去看我相关博客 这里只需要知道 哪怕大部分的程序都会将缓冲区设置为无缓冲模式 但是如果scanf函数一次性读入过多的字符串 其还是会调用malloc申请一个大chunk
而很多堆题 鉴于出题人的出题习惯或者是疏忽 在菜单页时选择的选项是由scanf函数来的
这也解决了我刚学堆时的疑问 为什么大部分都要用到atoi函数来中转 而不选择scanf直接读
1 | io.recvuntil(">") |
就以这题举例 此时利用scanf读入0x1000字节的‘1’
在此之前 没有进行任何的malloc调用 理论来说 此时heap应该还没有被初始化 但是在gdb中 我们是可以索引到top chunk的
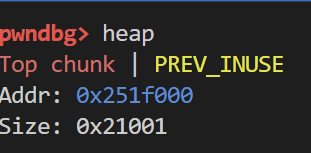
接着来查看一下top chunk的内容 可以看到都是1
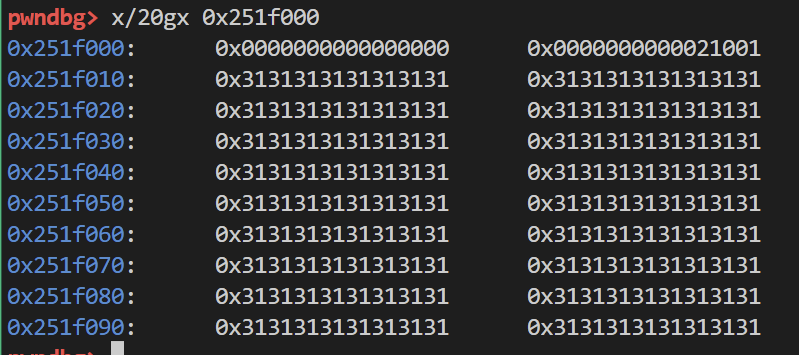
也就是说其申请了一个大chunk用来存放过多的字符串 随后释放到bin中和top chunk合并了
通过这个办法 就可以调用到malloc_consolidate 不过具体的调用流程我也不清楚 尝试过源码调试 但是也不知道打断点在哪里
怎样利用
可以用来利用的点 一个是刚才提到的 有些题目会对chunk的大小进行限制 从而没有办法释放chunk到unsortedbin 泄露libc基址 利用这种办法 只要是可以释放到fastbin中的chunk 都能进入unsortedbin
第二点 还需要一个特性相辅相成 不知道你有没有留意 在我们先前讲到的向前合并或者是向后合并 其是如何索引prev_chunk和next_chunk的呢 无非就是利用chunk头的那两个数值 size域就不动什么歪脑经了 修改后整个heap结构都会变化 那么目标自然是放在prev_size上了
你可能会想到利用堆溢出来覆盖prev_size 这个办法自然可行 不过我们先来观察一下利用malloc_consolidate形成的smallbin chunk
1 | for i in range(11): |
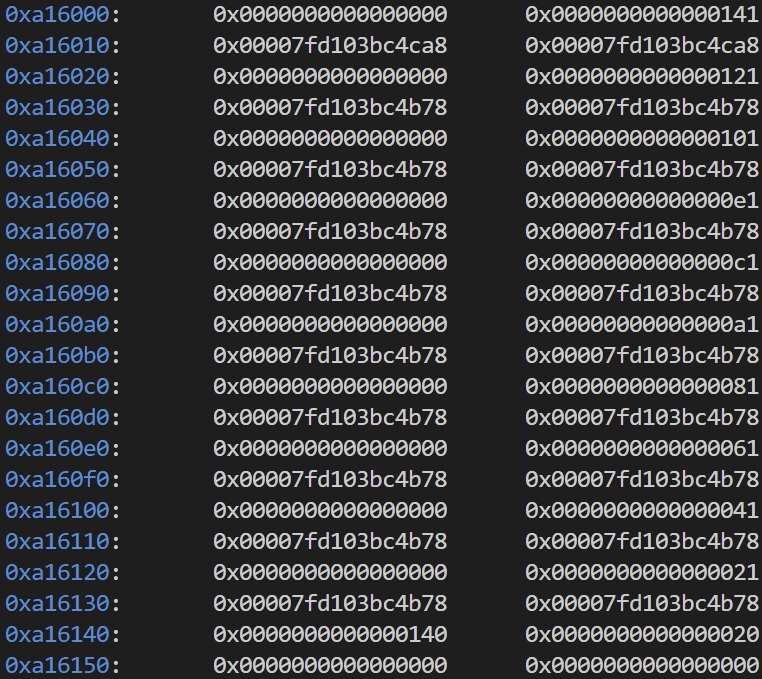

可以看到 虽然其合并成了一个0x140大小的chunk 但是在其内部 实际上还保留着原本chunk各自的size 并且size的值也可以表明是向后合并
基于这种数值的残留 存在着chunk overlap 下面跟着我一步步来看如何实现
1 | for i in range(11): |
此时的堆结构如图所示
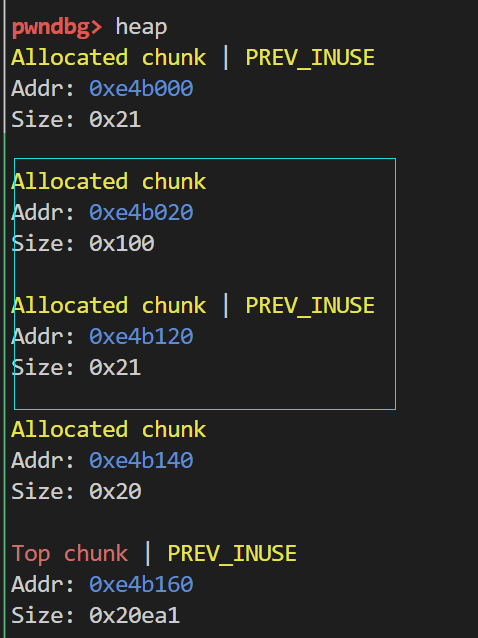
可以看到此时的smallbin已经被拆分成蓝框中的两个chunk了 我们利用chunk0溢出将chunk1的size域修改为0x100后 由于0xe4b020处残留着代表0x20大小的chunk头 所以形成了上图的情形
这样做的目的何在呢 可以看到此时最后一个chunk的prev_size为0x120 如果我们将其释放后 再利用malloc_consolidate就会索引到smallbin中的chunk 从而触发向后合并
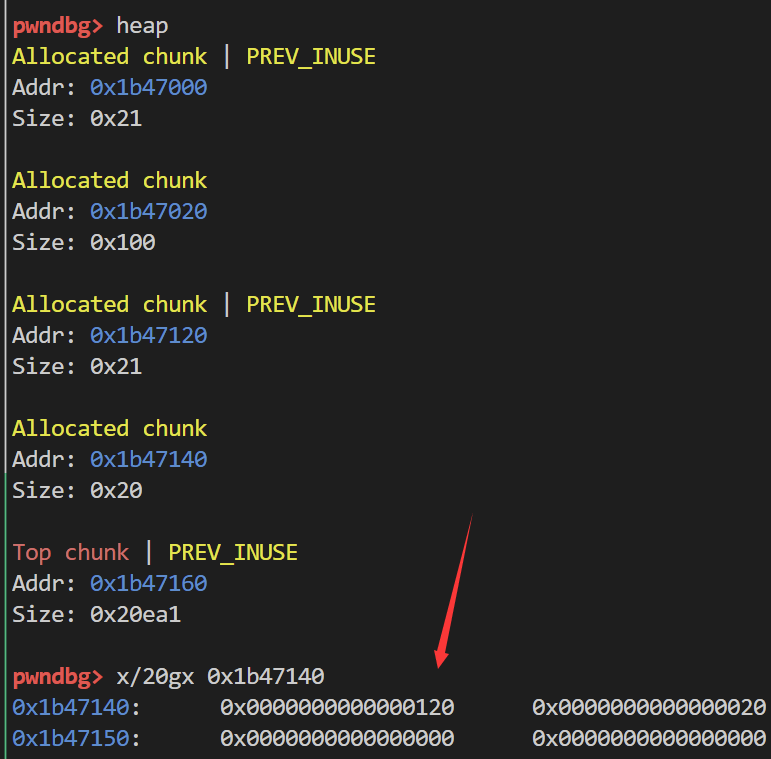
这样做的用意在于保留堆块指针 获得chunk overlap
1 | add(0x38)#11 |
此时我们再次申请四个0x38大小的chunk
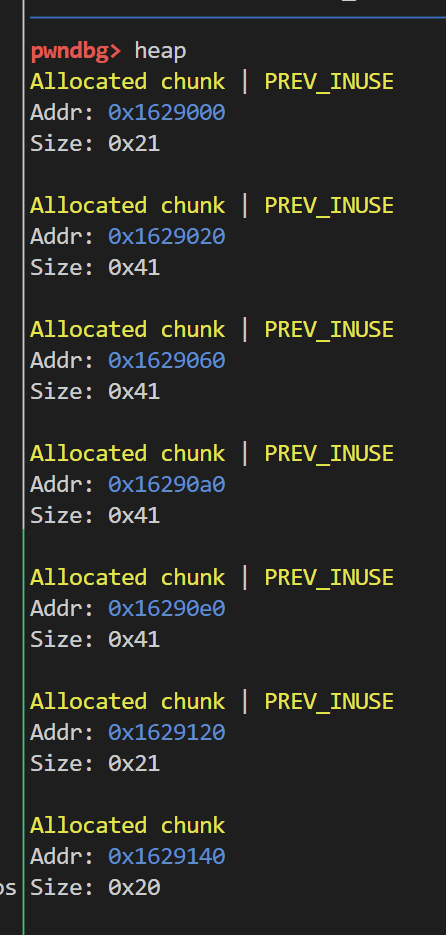
此时将smallbin瓜分完毕 随后我们释放前两个chunk 并且将其释放到smallbin中(其实一个也行 只要构造一个smallbin就行了 无关大小)
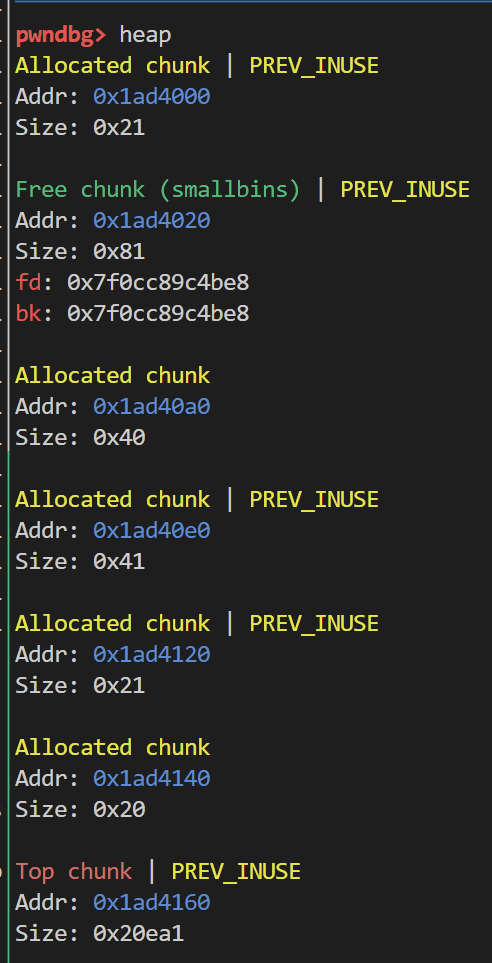
如果我们此时释放0x1ad4140这个chunk 其prev_size也就是0x120 索引到的就是smallbin 就会和其合并 从而中间的两个chunk的指针就会保留下来 如果我们再次申请 就会成功chunk overlap
1 | delete(10) |
完整:
1 | for i in range(11): |
ps: 大部分利用到这样攻击手法的 都没有堆溢出或者是UAF 所以上述的一些操作只是我为了方便演示 受限于情况需要另说 比如覆盖size域就可以通过off by null